DoubanMovie爬取

Contents
对豆瓣上的电影详细信息进行爬取,使用到的框架是 Scrapy。效率为24h爬取十万多部(效率可能不太高…)。记录一下爬取的过程和遇到的问题。
代码放在github:https://github.com/Alfonsxh/Spider
待爬取的站点信息
在 选影视 的这个页面:https://movie.douban.com/tag,最下面的 加载更多,点击后会出现新的电影信息。
F12打开chrome调试,在NetWork信息中,会发现每次触发了加载选项,会向服务器发送类似的请求,并且返回回来的电影信息为json格式!其中包含了具体电影信息的地址。
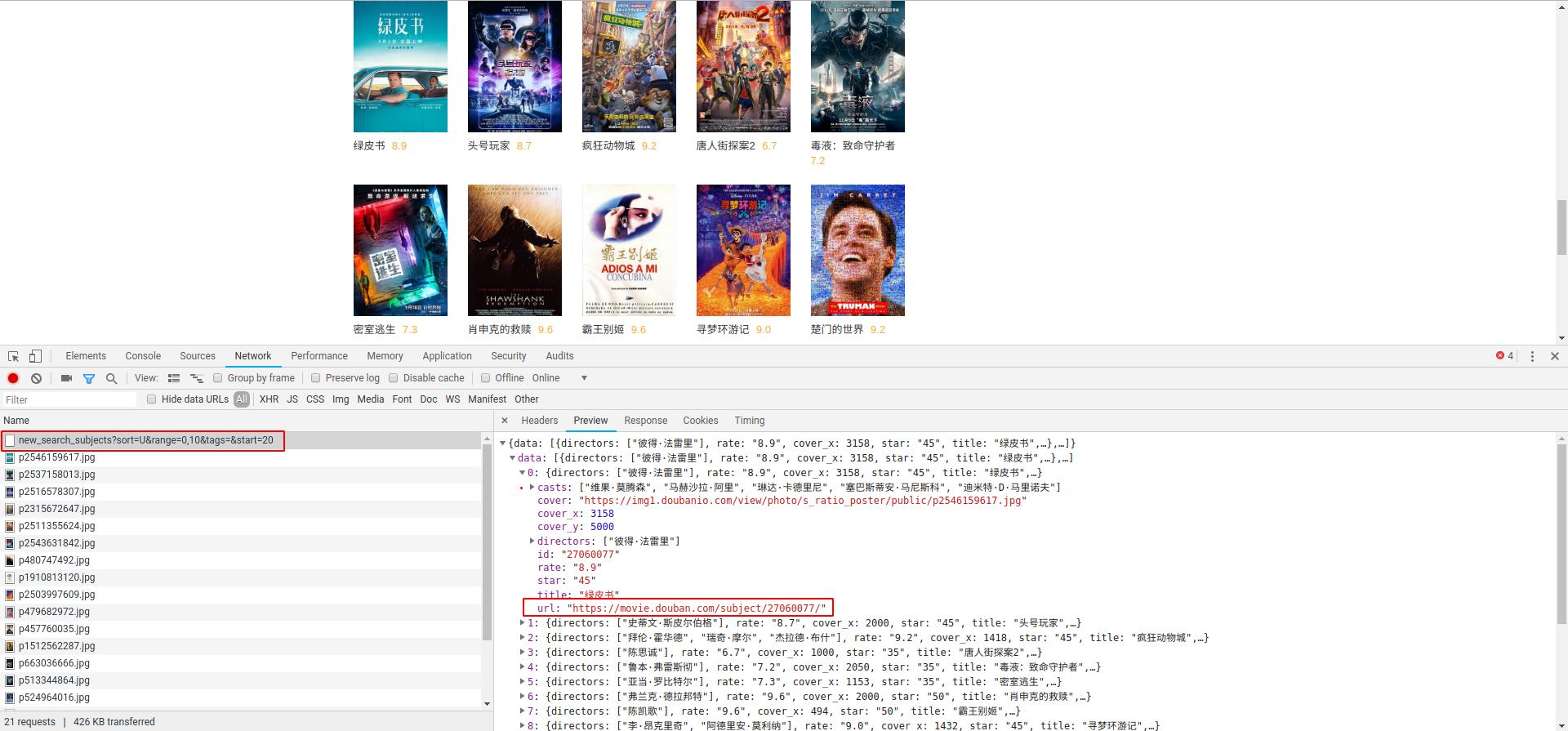
对应的请求响应地址为:https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=20
每次只改变了start后面跟着的索引号。于是,可以通过改变start索引的方式将大部分的影片的详细地址找出来。
不过,值得注意的是,start的值也是被限制的,大于一定值时,将不会返回结果。通过添加不同的过滤条件,可以将爬取到的电影数量尽可能的增多。
还有另外一种方式就比较暴力了。由于每部电影的详细信息地址都是下面的信息:https://movie.douban.com/subject/26636712/。末尾的数字ID即为电影的ID号,每部电影的ID号唯一。通过测试电影类型的ID号范围,遍历爬取这些ID号也可以。
与前一种方式相比,后一种方式能够爬取的电影信息数会更多,但不大推荐,毕竟是在爬取别人的服务器,互相理解。
爬取每部电影的信息
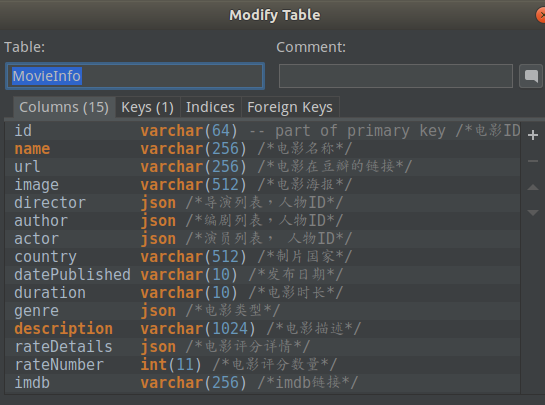
爬取的信息存储在mysql中,表结构如下:
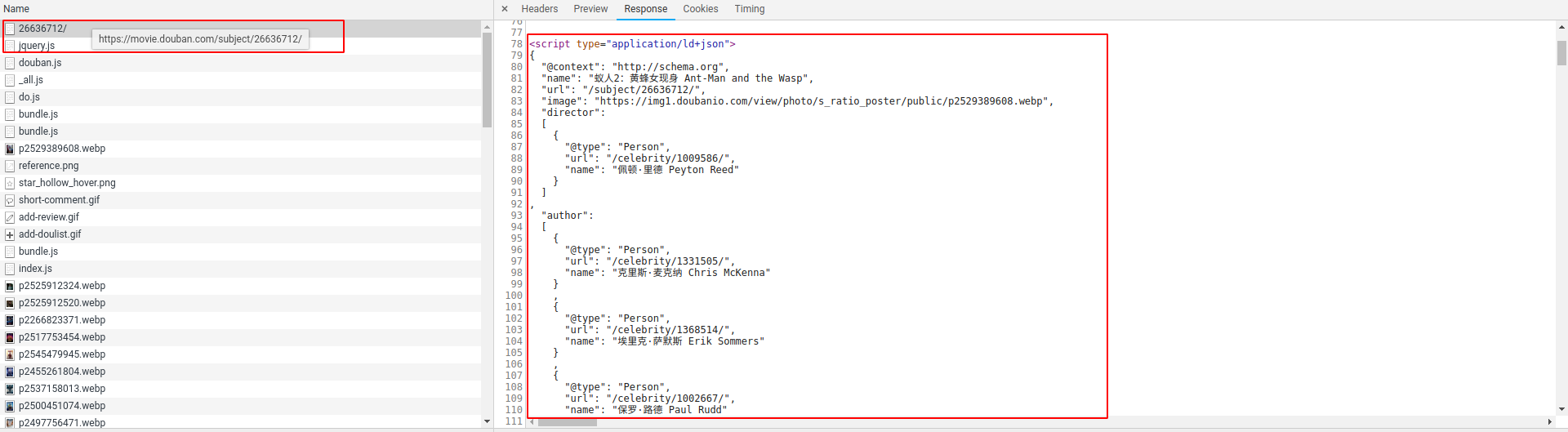
信息的来源有两处:
- 给google等搜索引擎提供的搜索js
- html页面
给google的搜索引擎提供搜索的js中包含了大部分有用的信息,入库的大部分数据也是这里取到的。这部分数据只要找到对应的json字符串,再转变一下,就很好取了。
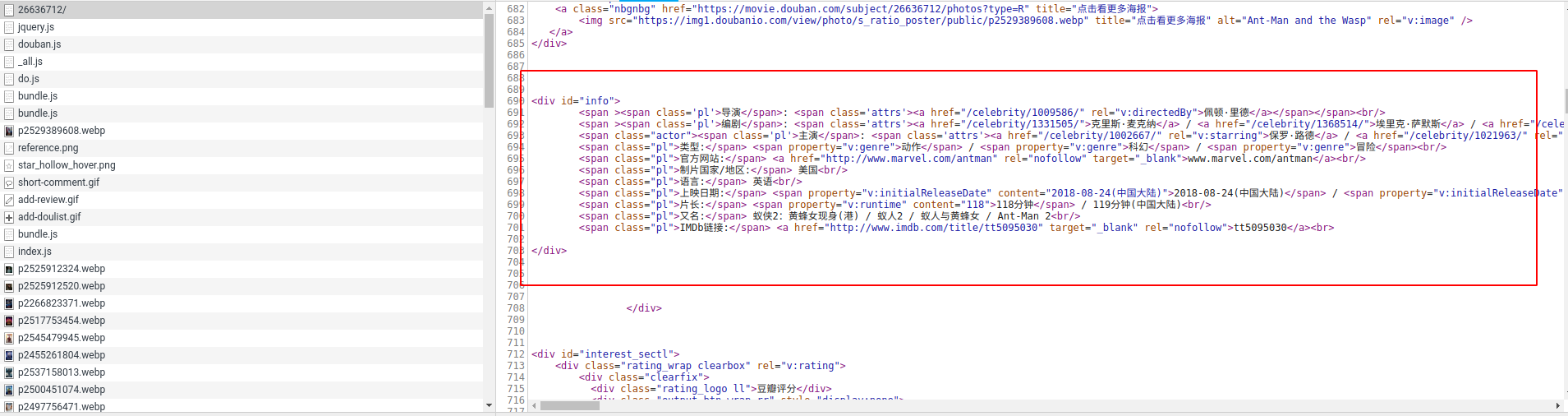
另一部分数据来源于html页面,需要编辑相应的xpath规则取得。
反爬策略
豆瓣的反爬策略还是很有效果的,同一ID一段时间内多次访问就会被屏蔽,需要输入账号密码后才能继续访问。
针对反爬策略有以下几点可以缓解。
更换User-Agent
更换 User-Agent 最基础了,可以在 setting.py 中设置参数 DEFAULT_REQUEST_HEADERS 方式实现,不过不推荐,同一个 User-Agent 被使用多次也会被封。
在 下载中间件 中,每次有新的 request 使用新的 User-Agent。
| |
使用代理
相同IP的频繁访问服务器也容易被封,在 下载中间件 中,每次有新的 request 使用新的代理IP。
| |
代理服务器选择了开源的一个: https://github.com/jhao104/proxy_pool。
更换Cookie
Cookie 中包含了一些关键字段,比如 bid。一段时间内频繁访问就有可能被要求验证登陆。
登陆又被分成了两种情况:无验证码登陆、有验证码处理。
无验证码登陆
无验证码登陆简单些,只需向验证服务器:https://accounts.douban.com/login,发送下面的form表单数据即可。
| |
有验证码处理
对于有验证码的服务处理起来就麻烦了一点,不过最关键的还是将验证码解出。
用了一种比较笨的方式:将验证码下载下来,人工判断。
| |
一种更为省力的方式为 通过机器学习,现在已经有了一些很好的模型,相对于豆瓣的验证码来说,准确度还是很高的。

不要按电影ID顺序访问,并控制访问频率
按照上面的做法,有时候仍然被封。通过随机访问电影网址,并控制访问频率的方式,能够降低被封的概率。